Dataware is an emerging approach to data architecture that seeks to eliminate the need for data integration. This article defines the basic attributes of a dataware platform, and gives a general overview of the approach.
 Through a series of blogs, webinars and a white paper Joe Hilleary shares these insights on data centralization approaches including dataware.
Through a series of blogs, webinars and a white paper Joe Hilleary shares these insights on data centralization approaches including dataware.
In 2021, the global market for data integration weighed in at more than $10 billion. If the present paradigm persists, that number will continue to increase exponentially, and companies will pay millions every year to build and maintain new data pipelines. Those pipelines will shunt copies of corporate data between different applications and analytics repositories, creating new silos and a data governance headache. But what if there were a different way? By fundamentally challenging the basic assumptions about how software should function, dataware proposes a novel way forward.
Dataware is an evolution in both technology and framework. The easiest way to understand it is to consider the history of the machine. Starting in the industrial age, enterprising engineers created tools that could perform specific tasks better and faster than human beings. From the first water-powered loom to coal-fired factories for the production of automobile parts, each machine was designed for a single task. Its form and function matched. One machine—one task. Then, in the 20th century, the computer came along. All of a sudden, a single machine could do many different tasks with the same underlying physical components. A computer separates form from function. The hardware (or form) still creates limitations, but ultimately, the software, a flexible set of instructions, determines the function.
The power of this freedom of function has defined the last 75 years. The whole world now runs on software. And software relies on data. Today, basically every piece of software incorporates a database of some kind. This database allows the software to store inputs and outputs as the computer carries out its instructions. Just as early machines fused form and function, software fuses instructions and data. Dataware seeks to decouple those two components. (See figure 1.)
Figure 1. The Evolution of Dataware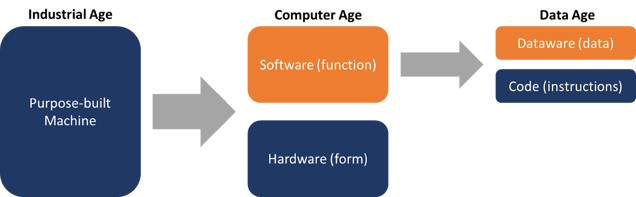
The present configuration of software that contains both a database and code works when a single program runs in isolation. Once multiple pieces of software begin to interact, however, that architecture becomes a liability. Data from one piece of software must travel to other applications, so that they can cooperate. Integration accomplishes this task by making a copy of the data in each application and moving it to all of the others. This approach results in the rapid proliferation of data pipelines and copies of data. All of which must be stored and maintained, increasing costs, complexity, and potential for error.
The dataware approach addresses this issue by taking the task of storing data away from individual applications. In this paradigm, software becomes responsible for the code alone. To accomplish a task, the software provides the instructions, dataware provides the data, and hardware provides the circuitry to physically execute everything. (See figure 2.)
Figure 2. Accomplishing a Task with Dataware
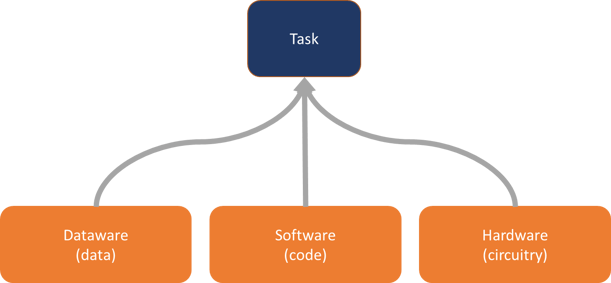
Like hardware, data becomes independent of a particular function. Just as the same piece of hardware can run multiple applications, the same piece of dataware can serve as the data source for any number of code-only apps. Engineers simply specify the dataware during software configuration in the same way they would configure software to run in on-premises or cloud-facilitated hardware environments. The instructions from the code access data from the dataware and run on the hardware. (See figure 3.)
Figure 3. The Relationship Between Dataware, Software, and Hardware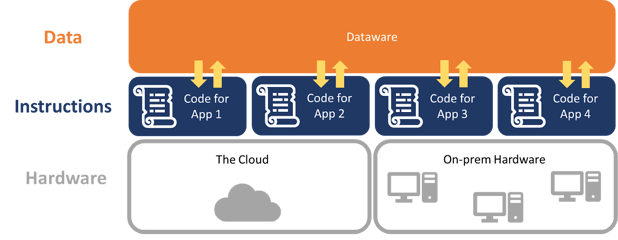
Dataware as a Base for Analytics
Although dataware sets out to solve a problem created by traditional approaches to software development, in doing so, it also solves a number of challenges for business analytics. Most analytics repositories, such as data warehouses, focus on using integration to provide a single source of business data for analysis. But in a world where the data is never separated into different application databases to begin with, the same repository that services applications can also function as a base for analytics.
Consider the traditional pattern for analytics repositories in figure 4:
Figure 4. The Basic Model of Analytics Dataflow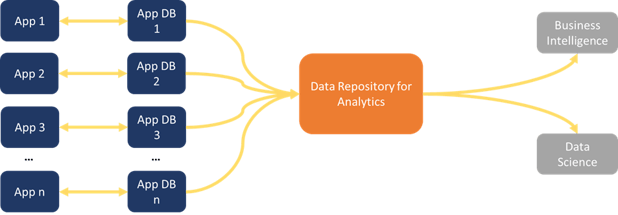
This pattern relies heavily on data integration, whether a data warehouse, data lake, or other repository, data has to move from various operational databases to one place where its accessible to analysts and data scientists to use it in their own workflows.
As shown in figure 5, dataware collapses this pattern by eliminating the need for application databases.
Figure 5. The Model of Analytics Dataflow with Dataware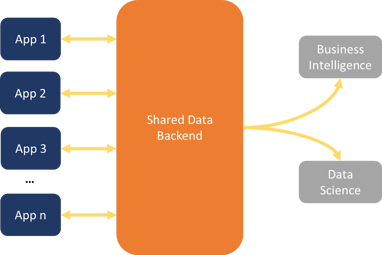
The data backend that feeds applications can also serve directly as an analytics repository--no additional integration required. We don’t have to centralize the data first, because the data was never decentralized.
Basic Attributes
As a theory, this is all well and good, but actually creating a platform capable of acting as dataware is non-trivial. Functioning dataware requires the following attributes:
Read and Write Capabilities
Dataware must allow users and applications not only to access data, but also to record new data.
Data Collaboration
In order for the entire approach to work, dataware must facilitate real time editing of data by multiple entities with shared access. Think about collaborating with colleagues on a Google Doc. Dataware needs that type of functionality, but for data. It also needs to enable collaboration between applications as well as human beings.
Operational and Analytical Base
Dataware must serve as the backend for both operational applications and analytics workflows. This means it must be accessible to both machines and humans. Applications must interact with it in the place of an operational database, while data analysts need to be able to query it like a data warehouse or other analytics repository.
Active Metadata Layer
Humans and applications both use different terminology when referring to the same things. As a result, dataware must have an active metadata layer. This layer serves to create semantic consistency. No matter what an application or individual might call a given field, the metadata layer will help the dataware platform provide the right information. In addition, the metadata layer will track collaboration, enabling traceback for edits.
Change Approval Process
Finally, dataware will provide a mechanism for approving changes to the data. In a user-based framework, dataware will enable data governance professionals to determine who or what applications may change which records. The dataware will permit organizations to implement access policies on a programmatic basis, so that the entire system can scale.
Conclusion
Dataware sets out to eliminate the need for integration by doing away with the concept of application-specific databases. Instead, a single shared data backend services all of an organization’s apps, which are able to collaboratively read and write to the repository in real time. This approach simultaneously gets to the root of a problem that has plagued analytics since its inception—the need to centralize data from multiple systems in order to answer business questions. As my colleague Wayne Eckerson is fond of saying, if Humpty Dumpty (our data) never fell off the wall, we wouldn’t have to put him back together again.
Want to learn more? Check out Joe’s white paper The Rise of Dataware: An Integration-Minimizing Approach to Data Architecture.
%20(1).png?width=318&name=The%20Rise%20of%20Dataware%20(1080%20%C3%97%201080%20px)%20(1).png)
Share this

The End of Integration

Modern Data Architectures: A Guide
