Making sense of data warehouse, data virtualization, data lakes, data lakehouses, data fabrics, and dataware

The world of data architecture can be overwhelming. Vendors throw around a dizzying number of terms and every couple of years it feels like a new one is tossed and thrown into the mix. In this article, I will seek to make sense of a handful of the most common approaches including data warehousing, data virtualization, data lakes, data lakehouses, data fabrics, and dataware.
The Data Warehouse
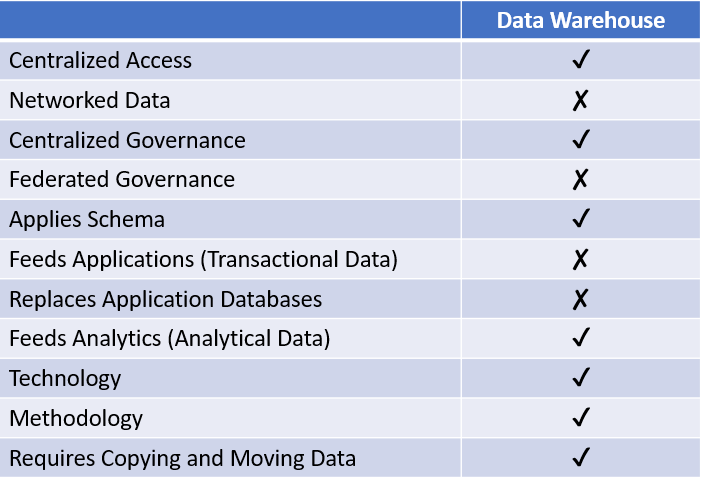
All other modern data architectures stem from the data warehouse. Invented in the 1990s and early 2000s, the data warehouse sought to bring together data from multiple sources in a single, centralized, structured data repository using a pre-defined model for business intelligence that facilitated easy queries for analytics.
Applications feed a data warehouse via pipelines or integrations, but a data warehouse doesn’t serve as an operational backend for those systems. It simply stores copies of data, which also continue to reside in separate databases. The sole goal of a data warehouse is to bring together structured data in a single location for analytics.
Data Virtualization
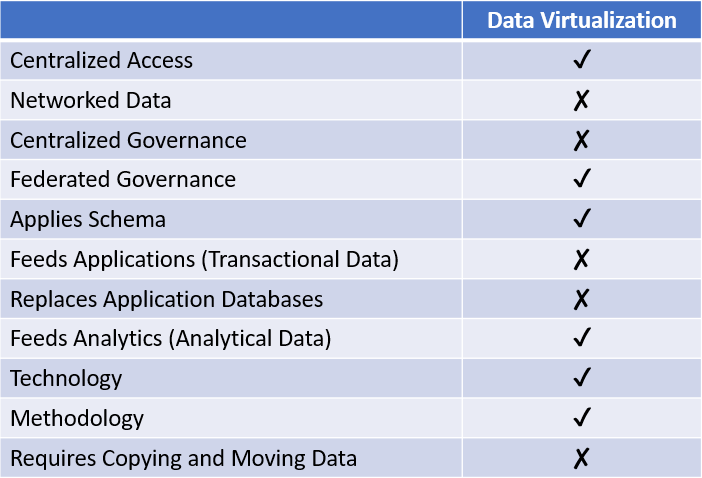
Data virtualization consists of a business view of distributed data that uses query federation to join data from heterogeneous systems in real time. Data virtualization shields business users from the complexity of backend systems, eliminates the need to move or copy data, and gives data administrators the ability to change those systems without impacting downstream reports and applications.
Essentially, it allows for the creation of a logical data warehouse. Users have the experience of using a centralized analytics repository, but, in reality, their queries go to the source systems. It facilitates the same centralized analytics as a data warehouse, but without need to physically copy or move the data, reducing the need for integration. Like a data warehouse, it does not replace operational databases for software, nor does it impact application to application integration.
A Data Lake
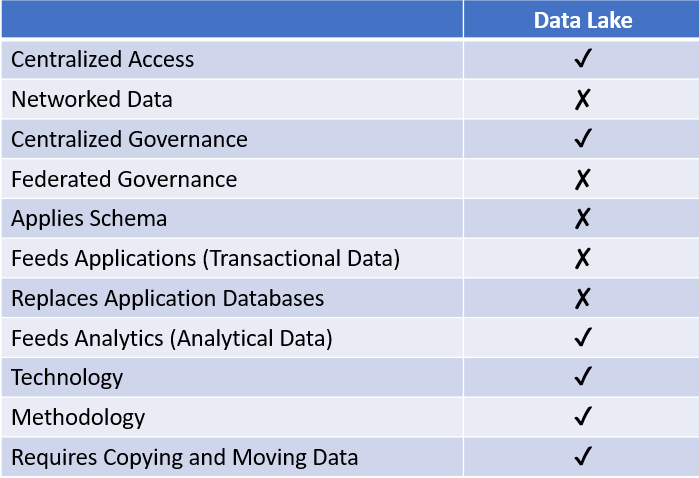
A data lake is a type of repository that stores structured, semi-structured and unstructured data in its native format. They originated as on-premises repositories running on Hadoop, but have evolved to run in the cloud as object stores. In the same way as a data warehouse, a data lake requires that pipelines carry copies of data from source applications to a central location where analysts or data scientists can query it. Unlike a data warehouse, it can accept unstructured data and does not impose a schema, but nonetheless it doesn’t support application development, nor does it reduce the need for integration.
A Data Lakehouse

A data lakehouse is a hybrid data repository that combines elements of a data lake and a data warehouse and supports multiple workloads including business intelligence, data science, and self-service analytics. At a minimum, it supports SQL constructs and cloud-native object stores. As with both the traditional data warehouse and the data lake, the data lakehouse focuses on analytics use cases. It cannot serve as the backend for an operational application. It also requires even more integration than either of its component parts because data travels first to the lake and then structured data moves again to a data warehouse-like structure within the lake.
A Data Fabric
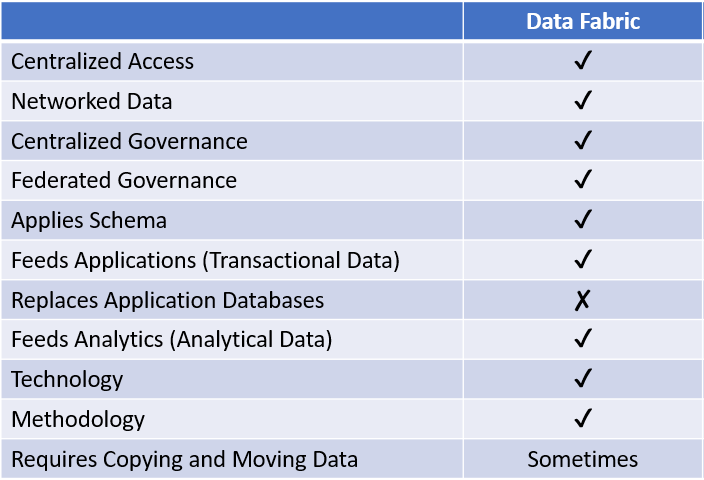
Data fabric is a recent, catch-all term used to describe a combination of architecture, services, and technology that delivers a unified semantic layer that works across any type of data, any source or target system, and any data infrastructure. The goal is to simplify user access and data management in a large, complex ecosystem.
Of all the present approaches, it is the closest to dataware. Like dataware, a data fabric does not require the copying or moving of data. Instead, both operational application and analytical queries rely on a network of repositories (the individual databases for applications). The data fabric presents a unified view of this network using virtualization. Dataware actually acts as a data fabric for applications that are not natively built using dataware in the place of an operational database. A traditional data fabric will always require applications to have their own databases that connect to the network, however, while dataware allows developers to build new applications without dedicated operational databases.
Dataware
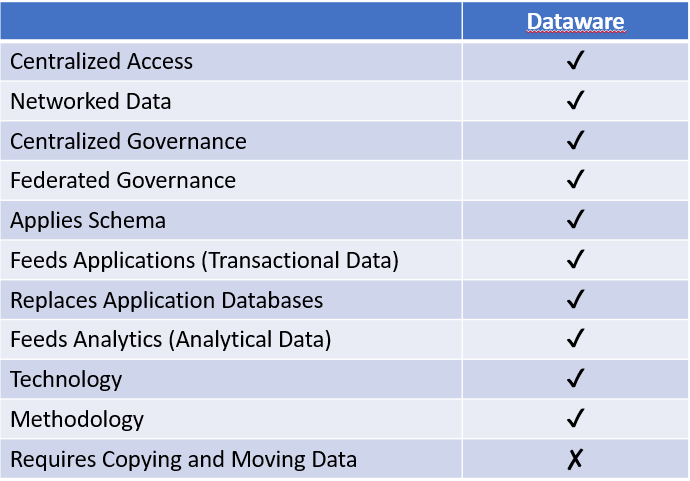
Dataware is an emerging architectural approach that aims to reduce or even eliminate the need for data integration both for analytics and for applications. It attacks the root cause of many of the symptomatic issues previous architectures tried to address—data silos at the application level. While most approaches to analytics repositories focus on bringing together data from the operational databases of applications, dataware attempts to prevent the data from ever being disaggregated in the first place. It serves as a repository not only for analytics, but also for applications, replacing the individual databases of applications with a single, shared data backend. Software becomes responsible for code alone, not storing data. In the short term, because most third-party applications are not designed to run on dataware, organizations can leverage dataware platforms to build data fabrics. This limits integration to only the initial connection to legacy applications and allows new applications to be developed directly on top of the dataware.
Conclusion
Within each of these categories there are a number of different approaches to implementation. Entire books have been written on topics like the different ways to structure a data warehouse schema. Rather than dive deeply on every one of these architectures, however, I chose to address the key contributions of each. Hopefully, that quick overview of their evolution has been useful to you. In parting, I’d like to emphasize that no one architecture is better than all the others. They each solve for different pain points, so knowing what they were intended to address will help you make better use of each where it suits your organization.
**A Note on Data Mesh
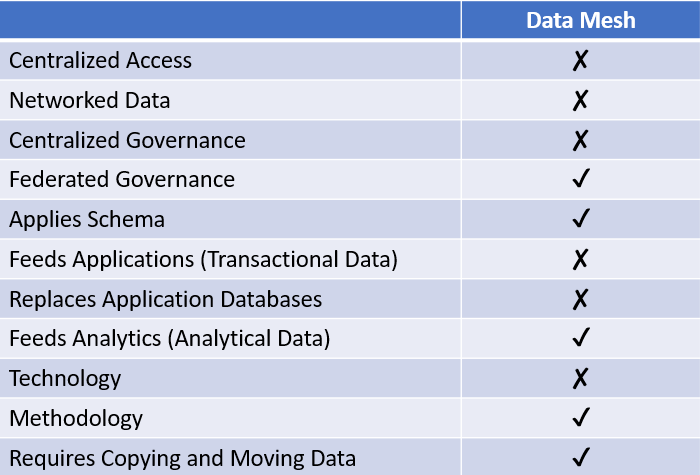
As an added footnote, I’d like to address “data mesh.” This term has gained a lot of traction in the last 18 months, and it’s worth understanding how the concept fits into the analytics architectures outlined above. Unlike the previous examples, data mesh is not a technology or repository. Instead, it is a distributed a governance framework in which business units own, manage, and publish data for others to consume. In a data mesh, data doesn’t move to a central location, instead consumers, such as corporate data analysts, get it from a department. It can be implemented using any number of different technologies but is well suited to similarly distributed technological approaches.
Want to learn more? Check out Joe’s white paper The Rise of Dataware: An Integration-Minimizing Approach to Data Architecture.
%20(1).png?width=318&name=The%20Rise%20of%20Dataware%20(1080%20%C3%97%201080%20px)%20(1).png)
Share this

The End of Integration

What is Dataware?
